Here I pose the following question:
Does the growth in COVID-19 cases have anything to do with Big 5 Personality traits?
To answer this question, I will need country-level aggregates on the Big 5 test, and a country-level aggregate that represents for “growth” over time in coronavirus cases.
Here’s how I operationalize it: I take all the countries that reached at least 50 “confirmed cases” of the coronavirus, using data that’s up to date as of March 20, 2020. Then I take the number of cases those countries had 14-days after reaching 50 confirmed cases. This gives an estimate of growth within a country that can be compared across countries, because it puts them all on a level playing-field.
Next, I compute country-level averages on the Big 5 Personality Test using data from the Open Source Psychometrics Project, and I only include countries with at least 1000 observations.
Finally, I look at the correlation between Confirmed Cases at Day 14 and average scores on each of the Big 5 personality traits (openness, conscientiousness, extraversion, agreeableness, neuroticism [a.k.a. emotional stability]).
For easy reference, the following datasets are used:
import pandas as pd
import numpy as np
import seaborn as sns
from matplotlib import pyplot as plt
from scipy.stats import pearsonr
import kaggleCOVID-19 Data¶
For the COVID-19 data, we’ll get the number of cases at 2-weeks after the first 50 confirmed cases.
# Download data from kaggle
# !kaggle competitions download -f train.csv covid19-global-forecasting-week-1
# !kaggle competitions download -f test.csv covid19-global-forecasting-week-1
# Join the training and test sets
covid19 = pd.concat([pd.read_csv('train.csv'), pd.read_csv('test.csv')])
# Sort by date
covid19.sort_values('Date')
# Filter to the columns we need
covid19 = covid19.loc[:, ['Country/Region', 'Date', 'ConfirmedCases']]
covid19.head()| Country/Region | Date | ConfirmedCases | |
|---|---|---|---|
| 0 | Afghanistan | 2020-01-22 | 0.0 |
| 1 | Afghanistan | 2020-01-23 | 0.0 |
| 2 | Afghanistan | 2020-01-24 | 0.0 |
| 3 | Afghanistan | 2020-01-25 | 0.0 |
| 4 | Afghanistan | 2020-01-26 | 0.0 |
Filter¶
Next we’ll filter to countries that reached at least 50 confirmed cases, and had at least 14 days of data beyond reaching that point.
covid19 = covid19[covid19.ConfirmedCases > 50]
covid19_numdays = covid19.loc[:, ['Country/Region', 'Date']]\
.drop_duplicates()\
.groupby('Country/Region')\
.count()\
.rename_axis('country')\
.reset_index()
print(covid19_numdays.head())
covid19_mindays = covid19_numdays[covid19_numdays.Date >= 14].reset_index()
covid19 = covid19[covid19['Country/Region'].isin(covid19_mindays.country)].reset_index() country Date
0 Albania 5
1 Algeria 5
2 Andorra 2
3 Argentina 5
4 Armenia 5What/how many countries does that leave us with?
print(len(list(set(covid19['Country/Region'].values))))
print(set(covid19['Country/Region'].values))21
{'Cruise Ship', 'Spain', 'United Kingdom', 'Singapore', 'Sweden', 'Kuwait', 'Bahrain', 'Germany', 'Iraq', 'Austria', 'Korea, South', 'Norway', 'China', 'Netherlands', 'Belgium', 'France', 'Malaysia', 'Switzerland', 'Iran', 'Japan', 'Italy'}Obviously “Cruise Ship” isn’t a country. I won’t worry about it at this point, since it will get filtered out in later steps.
Compute growth over 14 days¶
Next, we’ll compute the growth in cases for each country, from the date they reached 50 Confirmed Cases to the 14th day following that date. First we’ll need to collapse over province, since some countries are represented multiple times under different provinces.
covid19[covid19['Country/Region'] == 'China'].head()| index | Country/Region | Date | ConfirmedCases | |
|---|---|---|---|---|
| 47 | 2777 | China | 2020-01-26 | 60.0 |
| 48 | 2778 | China | 2020-01-27 | 70.0 |
| 49 | 2779 | China | 2020-01-28 | 106.0 |
| 50 | 2780 | China | 2020-01-29 | 152.0 |
| 51 | 2781 | China | 2020-01-30 | 200.0 |
covid19_collapse_province = covid19\
.groupby(['Country/Region', 'Date'])\
.sum()\
.reset_index()
covid19_collapse_province[covid19_collapse_province['Country/Region'] == 'China'].head()| Country/Region | Date | index | ConfirmedCases | |
|---|---|---|---|---|
| 47 | China | 2020-01-22 | 3540 | 444.0 |
| 48 | China | 2020-01-23 | 3541 | 444.0 |
| 49 | China | 2020-01-24 | 6612 | 602.0 |
| 50 | China | 2020-01-25 | 14172 | 958.0 |
| 51 | China | 2020-01-26 | 26818 | 1628.0 |
covid19 = covid19_collapse_province\
.groupby('Country/Region')\
.head(14)\
.groupby('Country/Region')\
.tail(1)
covid19| Country/Region | Date | index | ConfirmedCases | |
|---|---|---|---|---|
| 13 | Austria | 2020-03-19 | 1060 | 2013.0 |
| 28 | Bahrain | 2020-03-17 | 1176 | 228.0 |
| 45 | Belgium | 2020-03-19 | 1414 | 1795.0 |
| 60 | China | 2020-02-04 | 90949 | 23524.0 |
| 119 | Cruise Ship | 2020-02-20 | 5103 | 634.0 |
| 162 | France | 2020-03-12 | 6009 | 2281.0 |
| 184 | Germany | 2020-03-13 | 6718 | 3675.0 |
| 205 | Iran | 2020-03-08 | 7657 | 6566.0 |
| 231 | Iraq | 2020-03-20 | 7728 | 208.0 |
| 245 | Italy | 2020-03-06 | 7891 | 4636.0 |
| 273 | Japan | 2020-02-29 | 8003 | 241.0 |
| 307 | Korea, South | 2020-03-04 | 8302 | 5621.0 |
| 337 | Kuwait | 2020-03-15 | 8431 | 112.0 |
| 356 | Malaysia | 2020-03-19 | 8907 | 900.0 |
| 371 | Netherlands | 2020-03-18 | 9909 | 2051.0 |
| 387 | Norway | 2020-03-17 | 10144 | 1463.0 |
| 404 | Singapore | 2020-02-26 | 11481 | 93.0 |
| 441 | Spain | 2020-03-14 | 11793 | 6391.0 |
| 461 | Sweden | 2020-03-18 | 12033 | 1279.0 |
| 477 | Switzerland | 2020-03-16 | 12090 | 2200.0 |
| 495 | United Kingdom | 2020-03-16 | 16456 | 1543.0 |
Country Abbreviations¶
Next we’ll join in the country abbreviation codes. The source data here comes from the Kaggle Countries ISO Codes dataset, and the original source is Wikipedia. This will allow us to join to the Big 5 dataset later.
# !kaggle datasets download juanumusic/countries-iso-codes -f wikipedia-iso-country-codes.csv
country_isos = pd.read_csv('wikipedia-iso-country-codes.csv')
country_isos = country_isos.rename(columns={"English short name lower case": "Country/Region",
"Alpha-2 code": "country_abbr"})
country_isos = country_isos.loc[:, ['Country/Region', 'country_abbr']]
country_isos.head()| Country/Region | country_abbr | |
|---|---|---|
| 0 | Afghanistan | AF |
| 1 | Åland Islands | AX |
| 2 | Albania | AL |
| 3 | Algeria | DZ |
| 4 | American Samoa | AS |
covid19 = covid19.merge(country_isos, left_on='Country/Region', right_on='Country/Region')
covid19 = covid19.dropna()
covid19.head()| Country/Region | Date | index | ConfirmedCases | country_abbr | |
|---|---|---|---|---|---|
| 0 | Austria | 2020-03-19 | 1060 | 2013.0 | AT |
| 1 | Bahrain | 2020-03-17 | 1176 | 228.0 | BH |
| 2 | Belgium | 2020-03-19 | 1414 | 1795.0 | BE |
| 3 | China | 2020-02-04 | 90949 | 23524.0 | CN |
| 4 | France | 2020-03-12 | 6009 | 2281.0 | FR |
Big Five Personality Data¶
Next, we’ll fetch the Big Five Personality Test data from Kaggle. This dataset contains ~1M answers collected online by Open Psychometrics. I’m interested in this dataset because it also labels the country in which the respondant is located. We can use this dataset to get country-level aggregate data on personality traits, and then see if those traits map onto the COVID-19 outcomes that we’re seeing.
# Download data from Kaggle
# !kaggle datasets download tunguz/big-five-personality-test -f IPIP-FFM-data-8Nov2018/data-final.csv
# The file was zipped because it was so big, so unzip it
# import zipfile
# with zipfile.ZipFile('data-final.csv.zip', 'r') as zip_ref:
# zip_ref.extractall()
big5 = pd.read_csv('data-final.csv', sep='\t')Scoring the Big Five Personality Test items¶
The Big 5 personality inventory contains 5 factors. Like most personality scales, the Big 5 has a mix of items that positively and negatively load onto these personality factors. For example, the factor Extraversion describes someone who is outgoing, energetic, talkative, and enjoys human interaction. The first Extraversion item [EXT1] is “I am the life of the party.”, a positively-keyed item; whereas the second item [EXT2] is “I don’t talk a lot.”, a negatively-keyed item.
To find out which items are positively or negatively keyed, we can look at the scale documentation on the IPIP website: https://
Reverse-coding¶
Before analyzing the data from a personality test, a psychologist will generally “reverse-code” the items that are negatively-keyed. This results in a dataset where the item values all have a common direction and interpretetion (i.e., a higher value corresponds with more of that trait). Mathematically, it allows you to then compute sums and averages for each of the factors. For example, after scoring the test items, we could compute an individual’s average for Extraversion items to get their Extraversion score.
This version of the Big 5 scale asks individuals to rate their level of agreement from 1 to 5, where 1 is strong disagreement and 5 is strong agreement. Reverse-coding is as simple as subtracting 6 from every reverse-keyed item.
The code below will accomplish this task.
positively_keyed = ['EXT1', 'EXT3', 'EXT5', 'EXT7', 'EXT9',
'EST1', 'EST3', 'EST5', 'EST6', 'EST7', 'EST8', 'EST9', 'EST10',
'AGR2', 'AGR4', 'AGR6', 'AGR8', 'AGR9', 'AGR10',
'CSN1', 'CSN3', 'CSN5', 'CSN7', 'CSN9', 'CSN10',
'OPN1', 'OPN3', 'OPN5', 'OPN7', 'OPN8', 'OPN9', 'OPN10']
negatively_keyed = ['EXT2', 'EXT4', 'EXT6', 'EXT8', 'EXT10',
'EST2', 'EST4',
'AGR1', 'AGR3', 'AGR5', 'AGR7',
'CSN2', 'CSN4', 'CSN6', 'CSN8',
'OPN2', 'OPN4', 'OPN6']big5.loc[:, negatively_keyed] = 6 - big5.loc[:, negatively_keyed]Country-Level Big 5 Aggregates¶
First, we should eliminate any country that doesn’t have very many observations. Somewhat arbitrarily, we’ll draw a line at N = 1000.
big5_country_count = big5.country\
.value_counts()\
.rename_axis('country')\
.reset_index(name='counts')
print(len(big5_country_count[big5_country_count.counts > 1000]))
print(big5_country_count[big5_country_count.counts > 1000].country.values)58
['US' 'GB' 'CA' 'AU' 'PH' 'IN' 'DE' 'NONE' 'NZ' 'NO' 'MY' 'MX' 'SE' 'NL'
'SG' 'ID' 'BR' 'FR' 'DK' 'IE' 'IT' 'ES' 'PL' 'FI' 'RO' 'BE' 'ZA' 'CO'
'HK' 'PK' 'RU' 'AR' 'CH' 'AE' 'TR' 'PT' 'GR' 'VN' 'HR' 'AT' 'CL' 'RS'
'CZ' 'TH' 'JP' 'PE' 'KR' 'HU' 'IL' 'KE' 'CN' 'BG' 'VE' 'EC' 'LT' 'SA'
'EG' 'EE']There are 58 countries with at least 1000 observations. Let’s go with these.
big5 = big5[big5.country.isin(big5_country_count[big5_country_count.counts > 1000].country.values)]
# Filter on the columns we're going to use
big5 = big5.loc[:,['country'] + positively_keyed + negatively_keyed]Factor aggregation¶
Next, we’ll compute averages for each of the five factors at the level of the individual.
EXT = ['EXT' + str(i) for i in range(1,11)]
EST = ['EST' + str(i) for i in range(1,11)]
AGR = ['AGR' + str(i) for i in range(1,11)]
CSN = ['CSN' + str(i) for i in range(1,11)]
OPN = ['OPN' + str(i) for i in range(1,11)]big5['EXT'] = big5.loc[:, EXT].mean(axis=1)
big5['EST'] = big5.loc[:, EST].mean(axis=1)
big5['AGR'] = big5.loc[:, AGR].mean(axis=1)
big5['CSN'] = big5.loc[:, CSN].mean(axis=1)
big5['OPN'] = big5.loc[:, OPN].mean(axis=1)
big5 = big5.loc[:, ['country', 'EXT', 'EST', 'AGR', 'CSN', 'OPN']]Drop NAs, and any with country = ‘NONE’
big5 = big5.dropna()
big5 = big5[big5.country != 'NONE']Country-level averages¶
Now we can calculate the country-level averages.
big5_cavgs = big5.groupby('country')\
.mean()\
.rename_axis('country')\
.reset_index()Just to illustrate, these are the top 5 countries by country-level Extraversion scores.
big5_cavgs.loc[:, ['country', 'EXT']]\
.sort_values(by=['EXT'])\
.tail()\
.plot(x = 'country',
y = 'EXT',
kind='barh',
legend=False)
plt.show()
Joining Big 5 Country Data to COVID-19 Data¶
Next we’ll merge the COVID-19 dataset to the Big 5, country-level dataset.
covid19_big5 = covid19.merge(big5_cavgs, left_on='country_abbr', right_on='country')
covid19_big5.head()| Country/Region | Date | index | ConfirmedCases | country_abbr | country | EXT | EST | AGR | CSN | OPN | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Austria | 2020-03-19 | 1060 | 2013.0 | AT | AT | 2.992051 | 2.985863 | 3.678952 | 3.238528 | 4.056052 |
| 1 | Belgium | 2020-03-19 | 1414 | 1795.0 | BE | BE | 3.002726 | 3.049043 | 3.761206 | 3.197772 | 3.906212 |
| 2 | China | 2020-02-04 | 90949 | 23524.0 | CN | CN | 3.025746 | 2.947836 | 3.725448 | 3.310373 | 3.590299 |
| 3 | France | 2020-03-12 | 6009 | 2281.0 | FR | FR | 2.885782 | 3.126319 | 3.688029 | 3.193485 | 4.066059 |
| 4 | Germany | 2020-03-13 | 6718 | 3675.0 | DE | DE | 2.874198 | 3.007398 | 3.616373 | 3.220910 | 4.089598 |
factors = ['EXT', 'EST', 'AGR', 'CSN', 'OPN']
factor_names = ['Extraversion', 'Emotional Stability', 'Agreeableness', 'Conscientiousness', 'Openness']
for i, factor in enumerate(['EXT', 'EST', 'AGR', 'CSN', 'OPN']):
# Compute the correlation coefficient
corr = pearsonr(covid19_big5[factor], covid19_big5.ConfirmedCases)
corr = [np.round(c, 2) for c in corr]
text = 'r=%s, p=%s' % (corr[0], corr[1])
ax = sns.regplot(x=factor,
y="ConfirmedCases",
data=covid19_big5)
ax.set_title("Confirmed cases at 14 days after first 50 cases " +
"\n by average score on Big 5 factor " + factor_names[i] +
"\n" + text)
plt.show()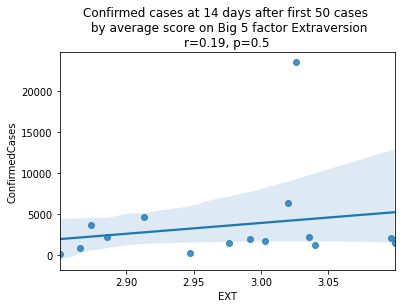

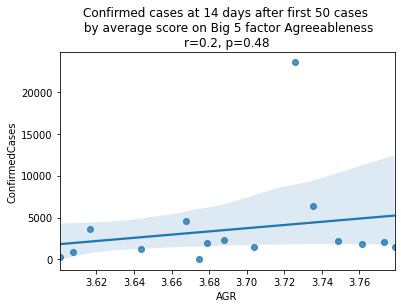
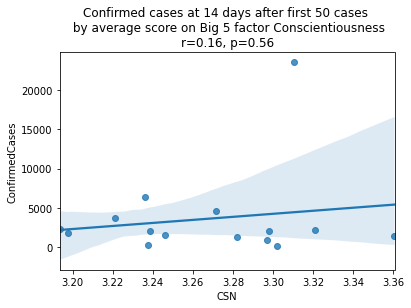
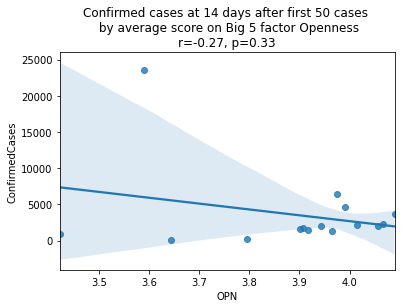
China is perhaps an atypical outlier here because it was where the outbreak started.
Let’s see the plots again without China.
factors = ['EXT', 'EST', 'AGR', 'CSN', 'OPN']
factor_names = ['Extraversion', 'Emotional Stability', 'Agreeableness', 'Conscientiousness', 'Openness']
for i, factor in enumerate(['EXT', 'EST', 'AGR', 'CSN', 'OPN']):
# Compute the correlation coefficient
corr = pearsonr(covid19_big5[covid19_big5.country != 'CN'][factor],
covid19_big5[covid19_big5.country != 'CN'].ConfirmedCases)
corr = [np.round(c, 2) for c in corr]
text = 'r=%s, p=%s' % (corr[0], corr[1])
ax = sns.regplot(x=factor,
y="ConfirmedCases",
data=covid19_big5[covid19_big5.country != 'CN'])
ax.set_title("Confirmed cases at 14 days after first 50 cases " +
"\n by average score on Big 5 factor " + factor_names[i] +
"\n" + text)
plt.show()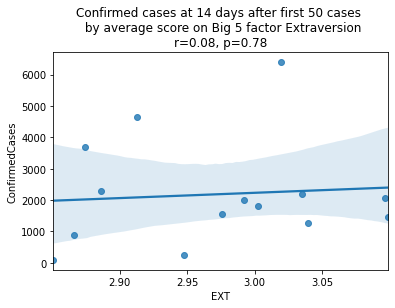
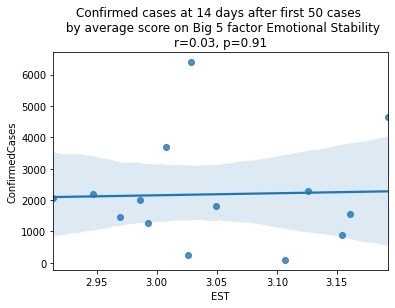

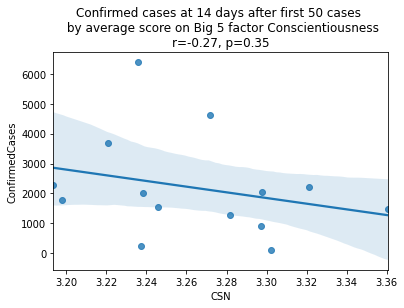
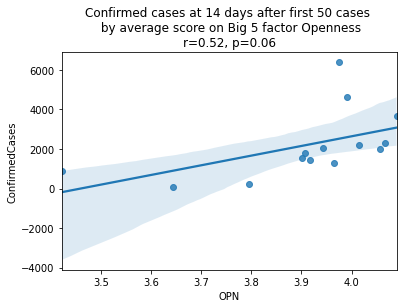
As we see here, the only Big 5 factor that seems to show a pattern was Openness: Countries with higher levels of openness saw more growth over the 14-day period.
Although a skeptic might point out that the countries lower on OPN had too much influence in the model, given how far they are set apart from the other data points, they artificially inflate the degree of fit.
covid19_big5\
.loc[:, ['country', 'OPN', 'ConfirmedCases']]\
.sort_values('OPN', ascending=False)\
.merge(country_isos,
left_on='country',
right_on='country_abbr')\
.drop(['country_abbr', 'country'], axis=1)| OPN | ConfirmedCases | Country/Region | |
|---|---|---|---|
| 0 | 4.089598 | 3675.0 | Germany |
| 1 | 4.066059 | 2281.0 | France |
| 2 | 4.056052 | 2013.0 | Austria |
| 3 | 4.015059 | 2200.0 | Switzerland |
| 4 | 3.991518 | 4636.0 | Italy |
| 5 | 3.974855 | 6391.0 | Spain |
| 6 | 3.965763 | 1279.0 | Sweden |
| 7 | 3.942170 | 2051.0 | Netherlands |
| 8 | 3.916673 | 1463.0 | Norway |
| 9 | 3.906212 | 1795.0 | Belgium |
| 10 | 3.901462 | 1543.0 | United Kingdom |
| 11 | 3.794982 | 241.0 | Japan |
| 12 | 3.643089 | 93.0 | Singapore |
| 13 | 3.590299 | 23524.0 | China |
| 14 | 3.422120 | 900.0 | Malaysia |